Spark
RDD
Resilient Distributed Dataset.
- Resilient: remain in memory or on disk on a "best effort" basis, can be recomputed if needs be
- Distributed
RDDs need not be collection of key-value pairs, it can be (ordered) collection of anything. But we do have one constraint: the values within the same RDD share the same static type.
RDD Lifecycle!!!
- Creation
- Transformation: transform one RDD into another RDD!
- Action
- A final action that make an output persistent!
- Lazy evaluation
- Creation and transformations on their own do NOTHING
- Only with an action that the entire computation pipeline is put into motion
Types of transformations
Unary
filter- input: a predicate function: take a value, return a
Boolean - return: subset of input satisfying the predicate
- preserve relative order
- input: a predicate function: take a value, return a
map- input: a function: take a value, return another value (one to one!!!)
- return: the list of values obtained by applying this function to each value in the input
flatMap:- input: a function: take a value, return 0, 1, or more values
- return: the list of values obtained by applying this function to each value in the input, flattening the obtained values (information on which values came from the same input value is lost)
flatMapIS THE SAME AS MapReduce's map, notmap!!!
distinct- input: comparator function (or none if the values are comparable)
- return: the list of values obtained by removing duplicates from the input
sample- input: none additional (just the input RDD)
- return: a subset of the input RDD (smaller than the input RDD)
Binary
unionintersectionsubtract: remove all elements from the first RDD (left) that are also in the second RDD (right)
Pair transformations
Spark has transformations specifically tailored for RDDs of key-value pairs!
key- return only the keys of the input RDD
values- return only the values of the input RDD
reduceByKeys- input: a (normally associative and commutative) binary operator
- return: a new RDD with the same keys as the input RDD, but with the values reduced by the binary operator (invokes and chians this operator on all values of the input RDD that share the same key)
- (k, (v1 + v2 + ... + vn)) is output assuming + is the operator.
reduceByKeyIS THE SAME AS MapReduce's reduce!!!
groupByKey- groups all kv pairs by key, and returns a single kv for each key where value is an array
sortByKeymapValues- Similar to the
maptransformation (notflatMap!), but map function only applied to the value and the key is kept
- Similar to the
join- works on two input RDDs or key-value pairs
- matches the pairs on both sides that have the same key
- outputs, for each match, an output pair with that shared key and a tuple with the two values from each side.
- If there are multiple values with the same key on any side (or both), then all possible combinations are output.
subtractByKey
Types of actions!
Gather output locally
By locally we mean in the client machine memory!
collect- downloads all values of an RDD on the client machine and output as a local list
- only use if the output is small enough to fit in memory
count- computes (in parallel) the total number of values (count duplicates!) in the input RDD
- safe for large RDDs bcuz only returns a smol integer
countByValue- computes (in parallel) the number of times each distinct value appears in the input RDD
- only use if the output is small enough to fit in memory
take- returns the first
nvalues of the input RDD
- returns the first
top- returns the last
nvalues of the input RDD
- returns the last
takeSample- returns a random sample of
nvalues from the input RDD
- returns a random sample of
reduce- input: a (normally associative and commutative) binary operator
- return: a new RDD with the operator invoked and chained on all values of the input RDD
- (v1 + v2 + ... + vn if + is the operator) and outputs the resulting value.
- no key!
- output is a single value?
Write output
saveAsTextFilesaveAsObjectFile
Actions for Pair RDDs
countByKey- outputs locally each key together with the number of values in the input taht are associated with this key
- a local list of key-value pairs
- only use if the the input RDD does not have lots of distinct keys
lookup- get the value or values associated with a given key
Physical Architecture
- narrow-dependency: computation involves only a single input
- wide-dependency: computation involves multiple inputs
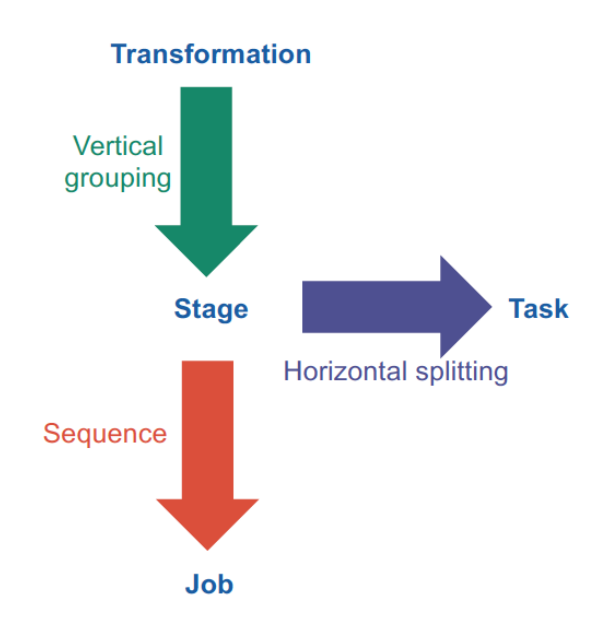
Stage: chain of narrow dependency transformations (map, filter, flatMap) etc (== phase in MapReduce)
Optimization
- Pinning RDDs
- Everytime an action is triggered, all the computations of the "reverse transitive closure" (i.e. all theway up the DAG thru the reverted edges) are set into motion.
- The intermediate RDDs in the shared subgraph is worthy to be pinned (persisted) in memory and/or on disk.
- Pre-partitioning
- If
Sparkknows that the data is already located where it should be, it will not perform shuffle - Example: when data is sorted before being grouped with the same keys after sorting
- If